안녕하세요! 파이썬으로 주식정보 크롤링 하기 3번째!
오늘은 가져온 데이터를 파일로 만들어 보겠습니다!
이번이 파이썬 크롤링 마지막 단계입니다! 화이팅!
이제 데이터를 추출해 볼까요?
df = pd.read_html(browser.page_source)
#andas 라이브러리의 read_html 함수를 사용하여 현재 Selenium WebDriver로 열린 브라우저의 페이지 소스를 가져와 HTML 표(table) 데이터를 DataFrame 형식으로 읽어옵니다.
#browser.page_source는 현재 브라우저 페이지의 HTML 소스 코드를 문자열로 반환합니다. 이 소스 코드에서 pandas의 read_html 함수는 표 데이터를 검색하고, 각각의 표 데이터를 DataFrame 형식으로 반환합니다. 따라서 코드의 실행 결과인 df는 DataFrame을 원소로 갖는 리스트입니다. 리스트의 각 원소는 웹 페이지에서 읽어온 표 데이터를 DataFrame으로 나타낸 것입니다.
len(df) #df 변수가 담고 있는 리스트의 길이를 반환

#네이버 시가총액 페이지에 해당하는 표 데이터의 개수가 3개 있다.
df[0] , df[1], df[2] 가 있다는 것을 알 수 있습니다.
그럼 df[0] 를 알아볼까요?
df[0]은 목록이 저장된 테이블인것 같습니다.
df[1] 이 원하는 데이터 인 듯 합니다.
df[2]는 어떤 번호인 듯 한데.... 잘모르겠어요
df = pd.read_html(browser.page_source)[1] 추가해 줍니다.
#NaN 을 없애고 싶습니다.
불필요한 데이터를 날리기 위해서는 추가 코드가 필요합니다.
이부분에서 세로 빈 줄이 전체다 NaN으로 인식되는 것 같습니다.
df.dropna(axis = 'index',how= 'all', inplace= True)
# axis = 'index'는 NaN 포함하는 행이 아닌 열을 삭제해야 함을 지정
# how = 'all'은 모든 NaN 포함하는 행만 삭제해야 함을 지정
# inplace = True는 데이터프레임을 변경하지 않고(즉, 데이터프레임의 새 복사본을 만들지 않고) 해당 데이터프레임을 수정해야 함을 지정
터미널에 입력을 하고
10줄만 출력 해 볼까요?
>>> df.head(10) 를 입력해 줍니다.
왼쪽이 수정한 값 입니다.
행에 NaN값이 없어졌죠?
성공!!
이제 열에 있는 NaN 값을 지워볼까요?
이부분에서 NaN 값이 나오는 것 같네요
df.dropna(axis = 'columns' , how= 'all' , inplace= True)
# axis = 'columns' 이부분만 index -> columns으로 바뀌었습니다.
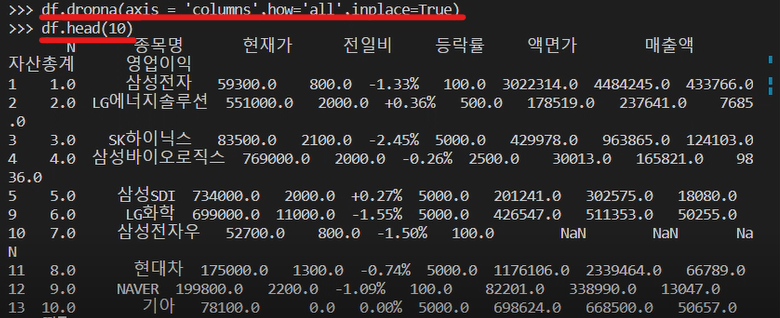
가로 세로 NaN 값이 없어졌어요!!
깔끔합니다.
이제 데이터 파일을 가져오는 작업을 해 볼까요?
'site.csv'라는 파일에 DataFrame(df)을 저장하는 코드
를 사용하려면
>>> import os
를 해야합니다.
f_name = 'site.csv' #f_name에 파일 이름 'site.csv'를 할당
if os.path.exists(f_name): #파일이 존재하는지 확인
df.to_csv(f_name,encodeing='utf-8-sig', index=False, mode='a', header=False)
#만약 파일이 존재한다면, df.to_csv 메서드를 사용하여 DataFrame을 해당 파일에 append mode(mode='a')로 저장
# encoding='utf-8-sig'은 UTF-8로 인코딩된 CSV 파일을 생성하는 것을 의미
else:
df.to_csv(f_name,encoding='utf-8-sig',index=False)
#파일이 존재하지 않는다면, df.to_csv 메서드를 사용하여 DataFrame을 해당 파일에 새로 저장
#위와 동일하게 encoding='utf-8-sig'은 UTF-8로 인코딩된 CSV 파일을 생성하는 것을 의미
# index=False는 CSV 파일에 인덱스를 포함시키지 않도록 설정

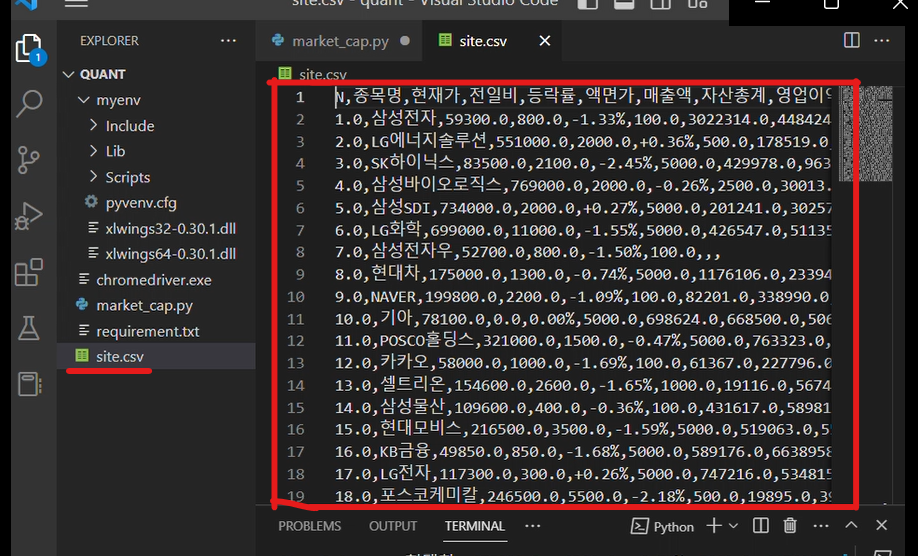
왼쪽에 site.csv 파일이 생겼습니다.
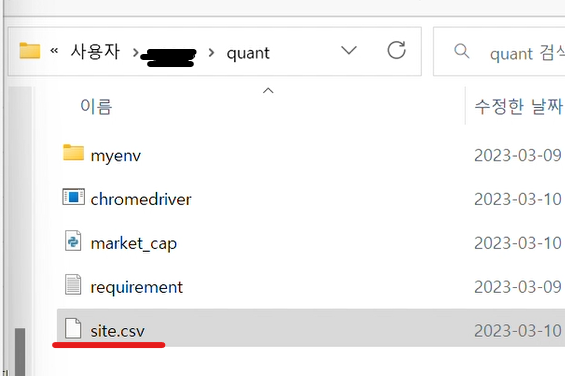
폴더에도 생겼네요
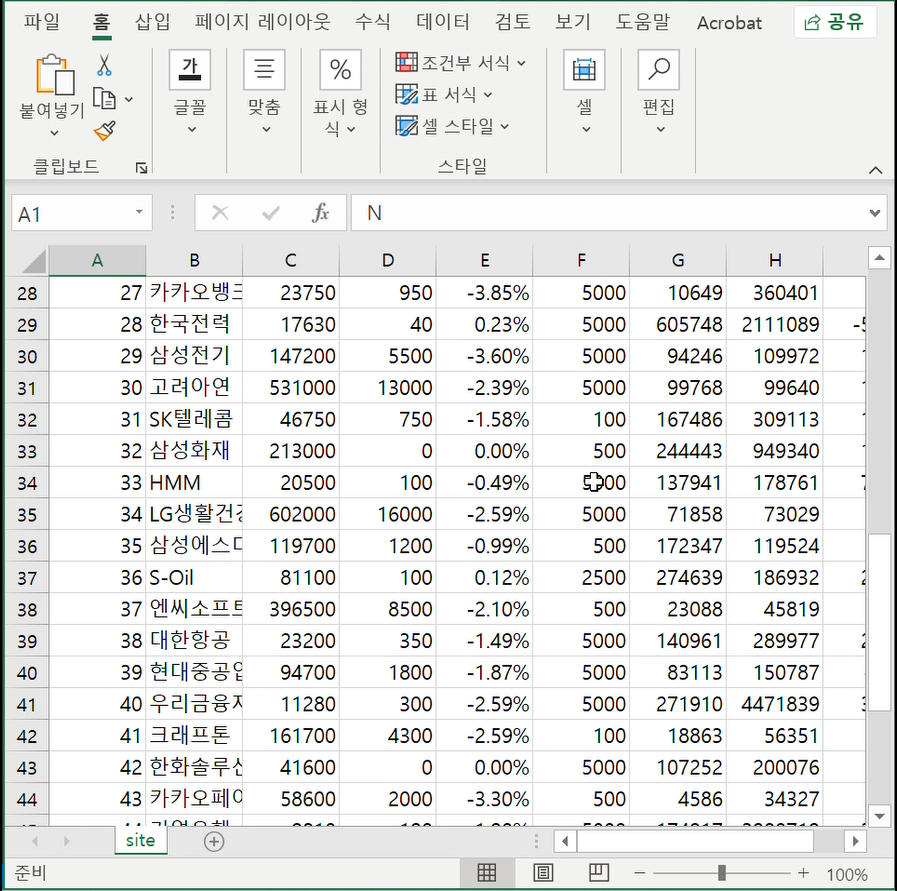
이렇게 생겼습니다.
print(f'{idx}페이지 완료')
# 네이버 시가총액 페이지는 총 37페이지가 있습니다. 한페이지가 완료되면 "페이지 완료" 가 출력되도록 코드를 짜줍니다.
총 37 페이지를 크롤링 하려면 반복문을 겉에 싸줘야 합니다.
for idx in range(1,40):
browser.get(url+str(idx))
##이 곳에 페이지 이동 코드 부터 입력해 줍니다.##
browser.quit() #브라우저 종료
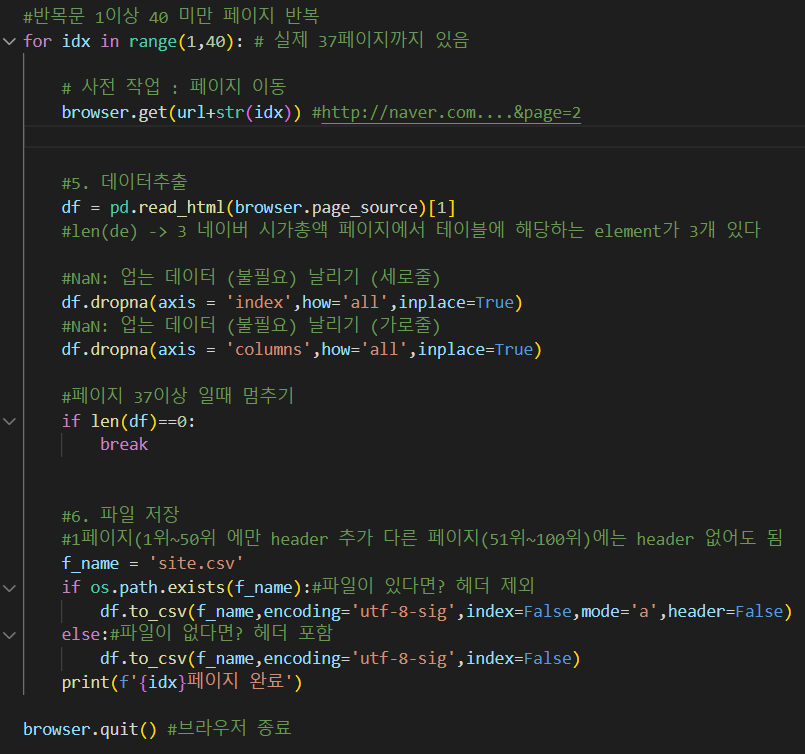
+ 추가로
if len(df) ==0:
break
를 써야 합니다.
페이지는 37 페이지여서 df의 데이터가 0 이면 멈추라는 명령어를 넣어 줍니다.
끝입니다!
휴 고생하셨습니다.
밑에는 결과 영상입니다.
지금까지 봐주셔서 감사하고
좋은 정보 되셨길 바라면서 저는 이만!!

[참고영상: https://youtu.be/ZDh1C7qw0Rs]
'IT 프로그래밍 > IT기기 이용' 카테고리의 다른 글
| 파이썬 주식정보 크롤링 하기(네이버 증권 페이지 이용하여 데이터 가져오기) [step2] (0) | 2023.03.16 |
|---|---|
| 파이썬 주식정보 크롤링 하기(네이버 증권 페이지 이용하여 데이터 가져오기) [step1] (0) | 2023.03.16 |
| 파이썬 가상환경 만들어 사용하기 (만들어서 패키지까지 설치!!) (0) | 2023.03.13 |
| 32기가 메모리 16기가 용 기기에 사용 가능하도록 만드는 방법! (32기가 메모리 16기가용 으로 나누기!) (2) | 2023.03.07 |




댓글